Stable Diffusion 3 AI Image Generator
Advanced text-to-image model for improved image fidelity
Free
5.0
What is Stable Diffusion 3 AI Image Generator?
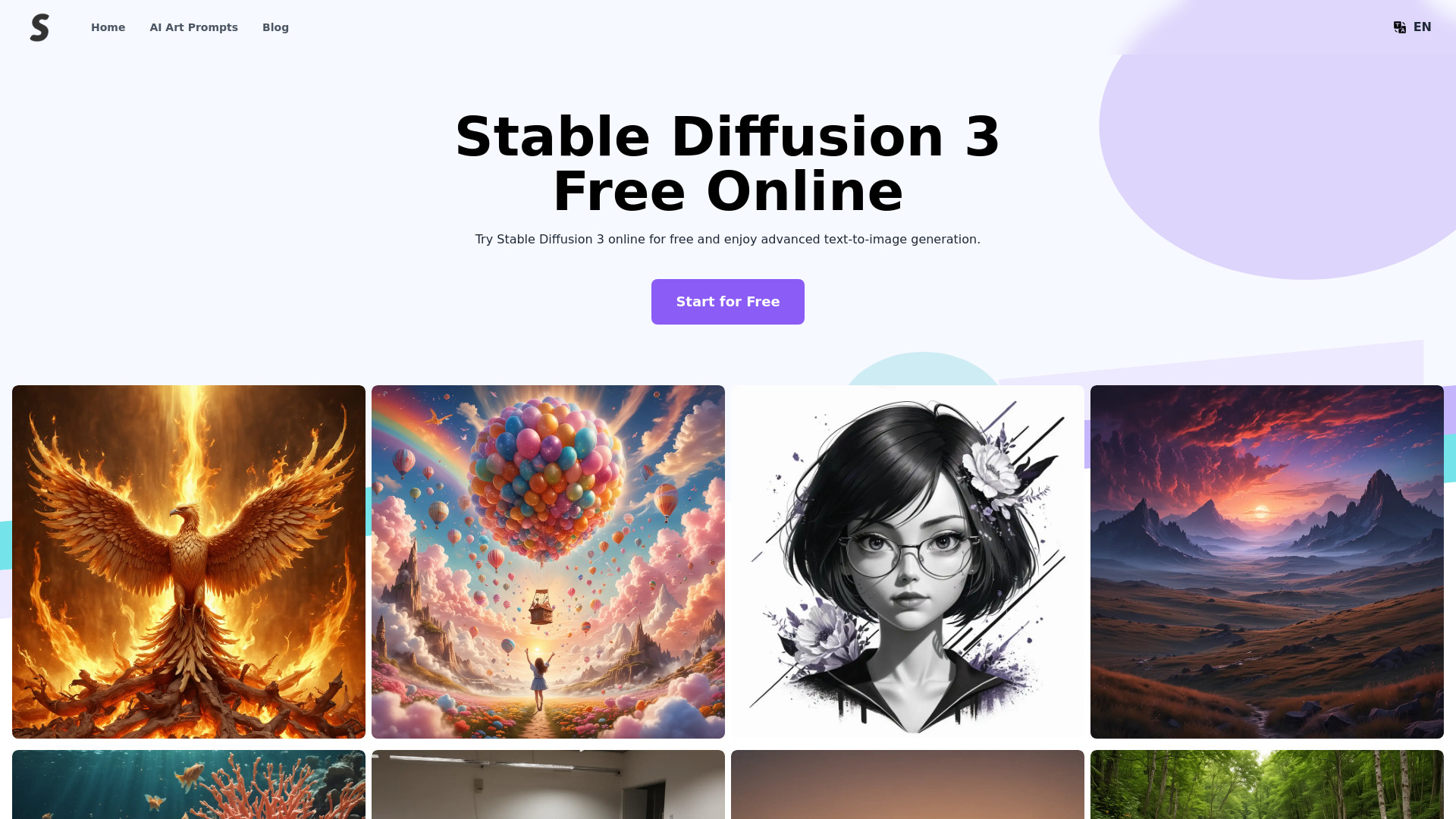
Stable Diffusion 3 is the latest and most advanced text-to-image model developed by Stability AI. It offers significant improvements in image fidelity, multi-subject handling, and text adherence. Leveraging the new Multimodal Diffusion Transformer (MMDiT) architecture, it features separate stable diffusion 3 weights for image and language representations. The model is accessible through various means, including the stable diffusion 3 API, stable diffusion 3 download options, and stable diffusion 3 online platforms.
About
Advanced text-to-image model for improved image fidelity
How to Use Stable Diffusion 3 AI Image Generator
To use Stable Diffusion 3, users can register on the website to receive a free quota. They can then input their text prompt into the provided interface to utilize the stable diffusion 3 weights for generating images. Once the AI generates the images, users can download them using the stable diffusion 3 download option.
Frequently Asked Questions
What is the stable diffusion 3 release date?
The stable diffusion 3 release date was June 12, 2024.
What are the benefits of using the stable diffusion 3 API?
The stable diffusion 3 API enables seamless integration and continuous updates, leveraging the latest features for advanced text-to-image generation.
What are the differences between stable diffusion 3 vs SDXL?
Stable Diffusion 3 offers improved text generation, adherence to prompts, and multi-subject handling compared to SDXL.
Where can I find stable diffusion 3 online resources and documentation?
You can find stable diffusion 3 online resources and documentation on stablediffusion3.net.
How does the stable diffusion 3 architecture differ from previous versions?
Stable Diffusion 3 leverages the Diffusion Transformer (DiT) architecture, integrating advanced noise predictors and sampling techniques to produce high-quality images.
Can I customize the stable diffusion 3 weights for specific applications?
Yes, Stable Diffusion 3 offers scalable stable diffusion 3 weights for detailed and accurate imagery for specific applications.
Quick Info
- Pricing
- free
- Platforms
- website
Best For
- Graphic designers for high-quality images
- Content marketers for accurate visuals
- Software developers for advanced text-to-image generation capabilities
- Educators for creating educational materials and visual aids
- Advertising agencies for high-quality advertisements and promotional materials
- Researchers for analyzing and visualizing complex data
Tags
#Text-to-image model#Image fidelity#Multi-subject handling#Advanced architecture#Scalable deployment#AI for graphic design#Visual content generation